innov’SAR core
For the optimization of polypeptides (peptides, proteins, enzymes, antibodies, VHHs).RAS module
For evaluating combination of Drugs (FDCs) in various diseases.AutomlSAR
AutomlSAR tests in parallel >135 algorithms and can be combined with innov’SAR core & RAS module.GraphMut
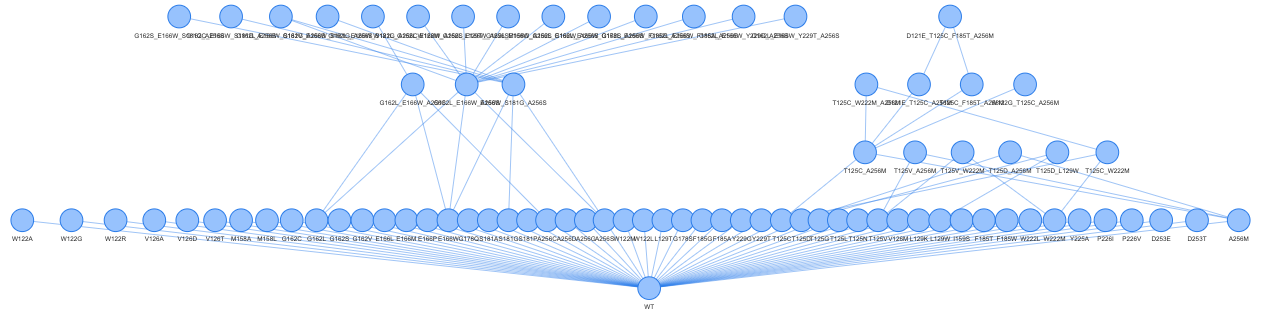
Graph-based visualization tool of relations between the mutations of protein sequence variants and activity variations.The application is coded with the shiny package.
Our proprietary innovative Sequence-Activity Relationship methodology, called innov’SAR core, identifies high fitness mutants from smart mutant libraries relying on physico-chemical properties of the amino acids, digital signal processing and regression techniques.
The novelty of Innov’SAR core is that it uses Fast Fourier Transform (FFT) to numerically encode protein sequences of a library of variants of the protein/enzyme with known activities into a set of protein spectra.
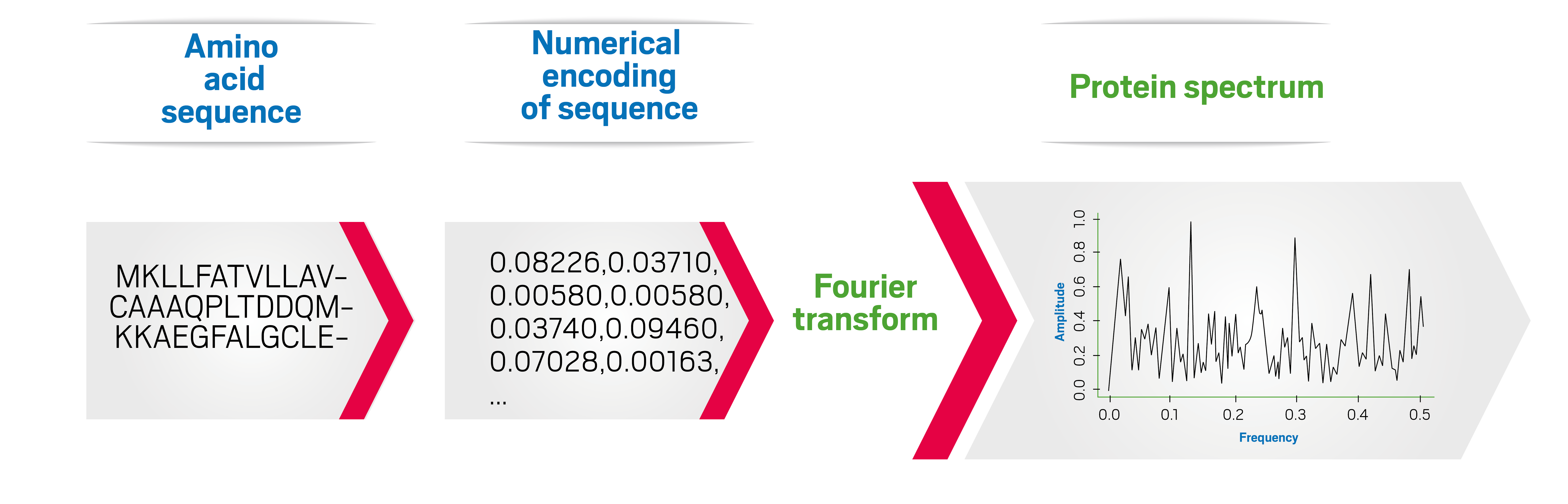 To sum up the basic characteristic of the procedure: Only an initial dataset containing the primary sequences of enzyme variants and the respective biological properties is required. It is different from other ML approaches due to the following characteristics:
To sum up the basic characteristic of the procedure: Only an initial dataset containing the primary sequences of enzyme variants and the respective biological properties is required. It is different from other ML approaches due to the following characteristics: Thanks to the Fourier transform, the non-linear aspects inside the protein sequence are captured;
Thanks to the Fourier transform, the non-linear aspects inside the protein sequence are captured; FFT allows to introduce new mutations at positions not previously explored or new positions of mutations;
FFT allows to introduce new mutations at positions not previously explored or new positions of mutations; A single round allows the identification of high performing mutants, while avoiding
A single round allows the identification of high performing mutants, while avoiding The need for excessively large datasets customary in other ML or deep learning approaches;
The need for excessively large datasets customary in other ML or deep learning approaches; No need for alignment-based amino acid descriptors, no need for protein sequences of equal length, as well as,
No need for alignment-based amino acid descriptors, no need for protein sequences of equal length, as well as, Large computational resources and/or long computational times are not required.
Large computational resources and/or long computational times are not required. The innov’SAR core approach is interpolative, extrapolative and predicts outside-the-box, not found in other state-of-the-art Machine Learning or Deep Learning approaches. The comparison of innov’SAR core with 14 other methods shows that it outperforms these SOTA ML & DL methods in terms of hit rate (81%).
The innov’SAR core approach is interpolative, extrapolative and predicts outside-the-box, not found in other state-of-the-art Machine Learning or Deep Learning approaches. The comparison of innov’SAR core with 14 other methods shows that it outperforms these SOTA ML & DL methods in terms of hit rate (81%).
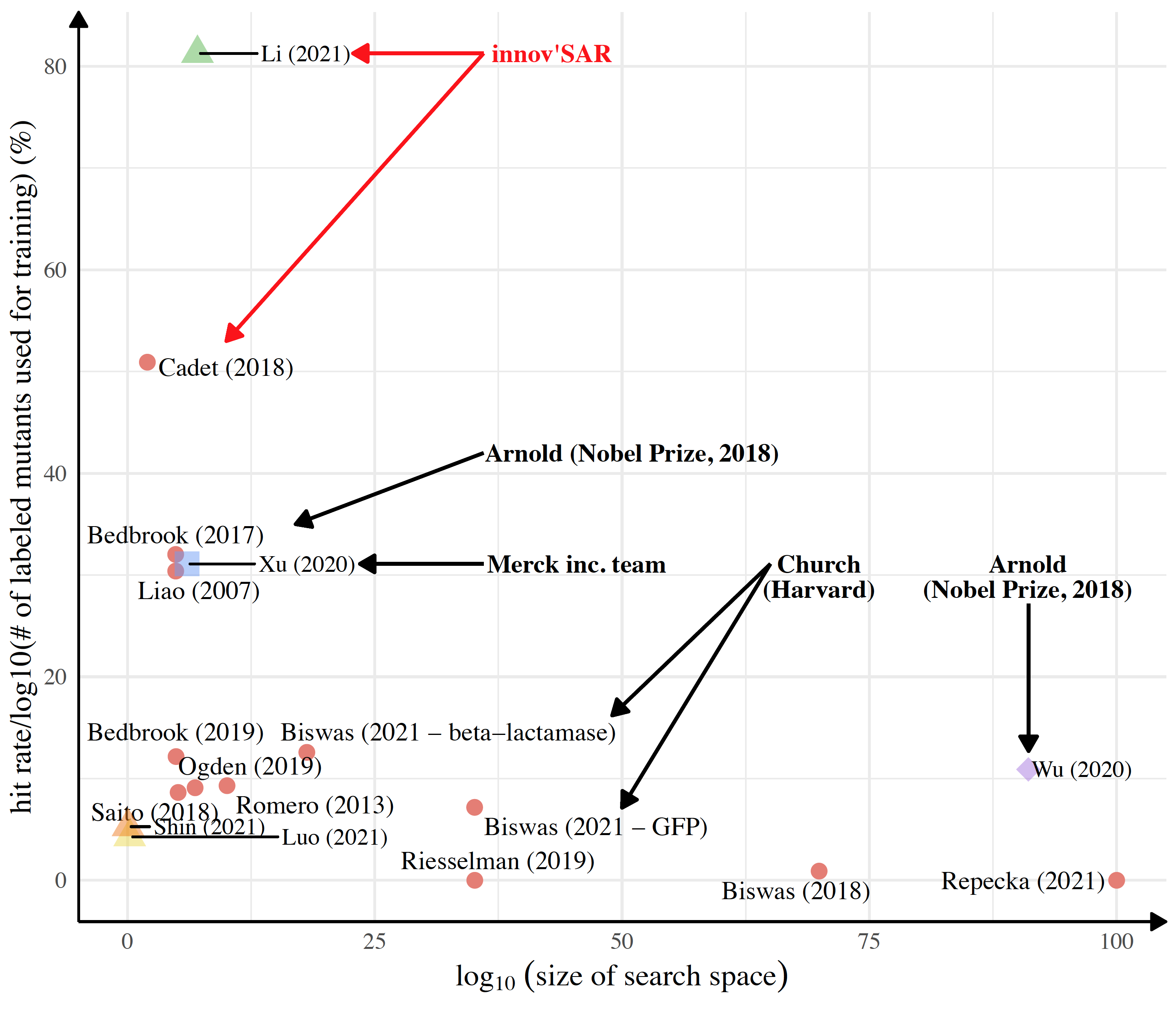
Relationship between the hit rate normalized to the log10 number of functionally characterized mutants used for training and the size of the search region explored: comparison of 15 studies. Turquoise blue square: assuming a non-normalized hit rate of maximum value of 1 (incomplete data to have the exact hit rate from the paper) for the CNN model proposed by Xu et al (2020). Purple diamond: The hit rate indicated in the Attention-Based Neural Networks model proposed by Wu et al (2020) is used for comparison.
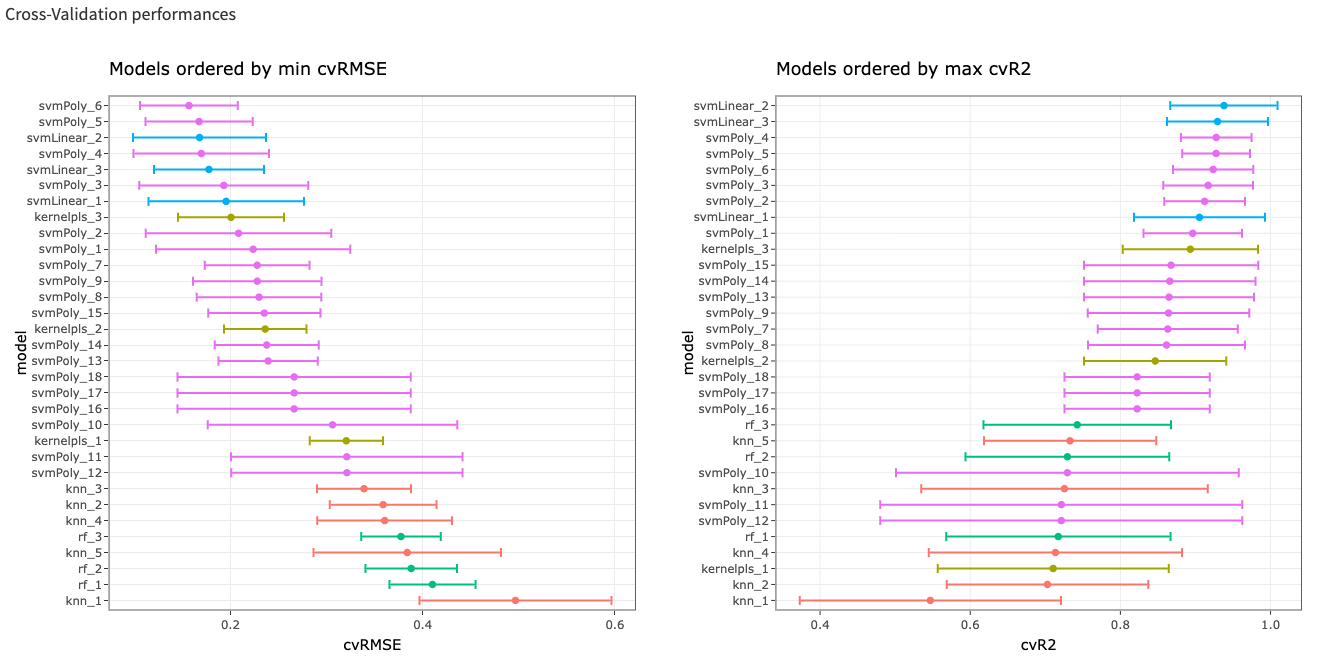
AutomlSAR is a tool developped by PEACCEL for the modeling of protein sequence- activity relation. It allows modeling of protein sequence-activity with deterministic regression algorithms (PLSR, Principal component regression, Lasso regression, Ridge regression models…), stochastic regression algorithms (ANOVA -analysis of variance- models; Linear, generalized linear, and nonlinear mixed models…), or black box type algorithms in models based on artificial neural networks. Different approaches of ensemble modeling such as staking, bagging, boosting are performed too. Nevertheless, whatever the approach chosen the difficulty will remain the final choice of a model among all the models tested. This choice will certainly be based on performance metrics, but when these indicators are very close, the choice becomes difficult: the experience and expertise of the researcher will then make it possible to select the final model. In the example below, only 5 algorithms (pls, svmLinear, svmPoly, rf, knn) are examplied. AutomlSAR tests in parallel >135 algorithms and can be combined with innov’SAR core & RAS module.
GraphMut generates a graph based on the mutation relations between the protein sequences of a dataset.
This tool allows you to visualize with a single glance the complexity of the relationships between the different sequences. This approach provides information on the mutations to be avoided and the one to be favoured.